Among all the sophisticated performance and storage hacks you can use to get things right in Snowflake such as caching, search optimization, warehouse scaling and so on; I want to give you very simple but extremely useful 5 tips that you can start using in your daily operations right away. Below you can see a list of them.
Let’s start with my favorite one;
1- Too many transactions on a table means too much fail safe storage that is being consumed. Unless.. The table type is not permanent..
Let me clarify this. Snowflake has time traveling feature that makes most of the data professionals feel safe around this database. But it comes with a cost. And the cost is of course; the storage. Well, sadly more than the amount of the storage that we use for time traveling, actually. When we use permanent tables in Snowflake we can get the most out of time-traveling feature as it lets us travel in time up to 90 days, while transient and temporary tables are capable of going back in time just one single day. And in addition to traveling in time for so long, permanent tables store the data 7 days more after the retention period ends. BUT.. Here is this big BUT.. Every time there is an update, delete or any changes happening on a permanent table, the table is backed up in the fail-safe area following the retention period. Every transaction that is made consumes much more space than the storage area that is consumed during time-traveling period.
If we think of organizations having massive amount of data; using permanent tables for executing your transactions is the unthinkable. So pals, just an advice. Use transient tables to perform your transactions on your stages and use permanent tables as the eventual target for your data. And thank me later 😉
2- Insert the data in the table in a sorted way.
Well, this is a real hack! I call this one the cluster hack. While inserting data in the the table; sorting the data on the column you will use the most for joining and aggregation purposes; can have a significant effect on the query performance. Especially if the table is big. The reason why we want to do that, is to imitate the way clusters work without the cost of it. As you may know, the clusters are the objects on tables that are being used to keep the micro-partitions sorted on the columns we choose. In this way it is easier for the parser to know which partitions will be scanned when we query them, so we would not need to bring all the partitions in the game if we knew which ones we specifically needed. Sorting the columns behaves exactly the same way clusters behave. And voila! Better query performance without clustering cost. Fair enough, isn’t it?
3- Do not fetch all the columns of a table while executing a query if you don’t need them at all.
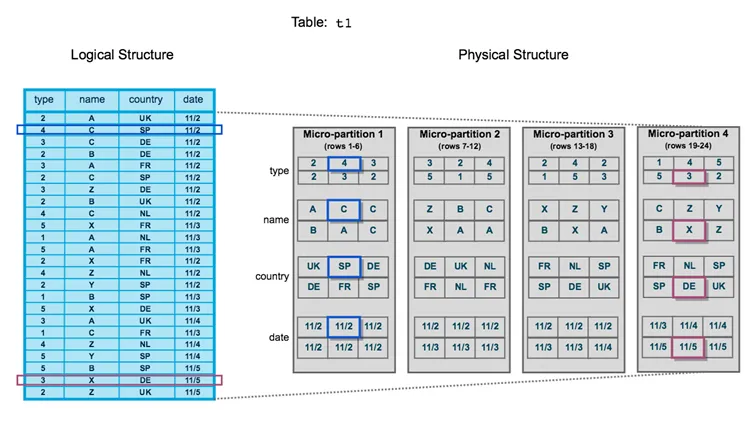
Snowflake holds the data in columnar format in the micro-partitions. Fetching all the columns will result in fetching all the micro-partitions. I don’t think we want that as people working with data as it will keep the resources busy and gets more data in the play. Below you can see a picture of physical structure of the data in the database storage layer and how it keeps the data in columnar format in the micro-partitions.
4- Limit the number of rows you fetch in your queries while analyzing your data and tables.
To put this in another way, don’t scan all your partitions if you don’t need the whole data. You don’t want to consume too many credits and resources for something you do not need, rather than using the resources for some other jobs waiting in the queue, right? Limiting the number of rows you are fetching will basically limit the number of partitions you are scanning.
5- If you will update more than %80 of a table just delete all the data and insert the whole table with the updated version of the data instead.
In my previous post on Medium, I described how metadata operations are done under the hood when we update/delete or insert data in a table. When we are updating data, we do not update directly the micro-partitions in Snowflake as they are immutable. We add new partitions to the files in the storage layer and change the information in the metadata manager in cloud services layer with the new partition information. So, updating table is basically inserting new partitions on the files and changing the information in metadata manager rather than directly updating the partitions. If the amount of the data you update in a table is more than %80, being persistent on executing update operation would be very costly. Not only that, it would be much of a hassle. The smartest way would be just deleting the data in the table and inserting the new updated version of the data. If you want to read more about the logic of metadata operations and micro-partitions, you can check the article I posted lately. ( HOW TIME TRAVELING IN SNOWFLAKE WORKS UNDER THE HOOD | by Asli Imre | Jan, 2024 | Medium )