This blog describes how metadata operations work under the hood in Snowflake to achieve time traveling, zero-copy cloning and data sharing features. Snowflake uses metadata operations, advantages of separation of concerns as it is built on 3-layered architecture and most importantly immutable files that cannot be modified in any terms. Metadata operations and immutable files are the core components of the logic which makes time traveling, zero copy cloning and data sharing possible. Below I describe how that is done. If you are already familiar with Snowflake architecture and micro-partitions, you can skip these parts and see “Metadata Operations” in the article.
ARCHITECTURE
Snowflake architecture consists of 3 layers that work together where objects are not tightly coupled. Below you can see a diagram which describes the architecture of Snowflake. Cloud services layer is the brain of the architecture where user interactions take place, metadata operations are handled, queries are optimized, authentication and access control are managed. The queries are passed from cloud services layer to query processing layer and are processed here by instantly scalable virtual warehouses while data is stored in database storage layer in immutable (unchangeable) files within micro-partitions.
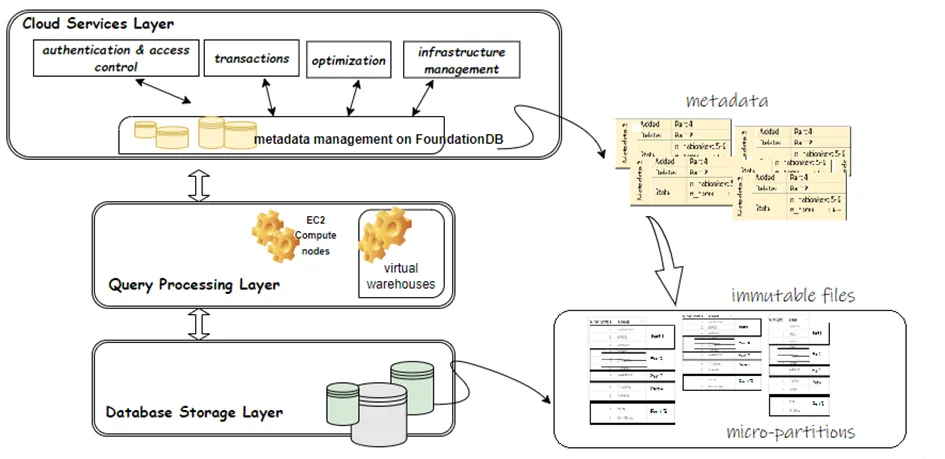
MICRO-PARTITIONS AND STORAGE LAYER
Micro-partitions are where pre-indexed, fine-grained data is stored in columnar format along with metadata statistics in 16 MB variable length data chunks. They are written in immutable files in database storage layer. Files typically contain multiple micro-partitions can vary between 50 and 500 MB. Being able to store the data in small data chunks as micro-partitions makes it possible to store the data in the tables in extremely granular form. Very large tables can be pruned into small granular micro-partitions that are managed by metadata manager in Cloud Services.

METADATA OPERATIONS
Metadata holds the information corresponding with micro-partitions in cloud storage and are stored separately in metadata manager that is built on FOUNDATIONDB in cloud service layer. Information that is stored in metadata are;
- The range of values for each of the columns in the micro-partition.-
- The number of distinct values.
- Additional properties used for both optimization and efficient query processing.
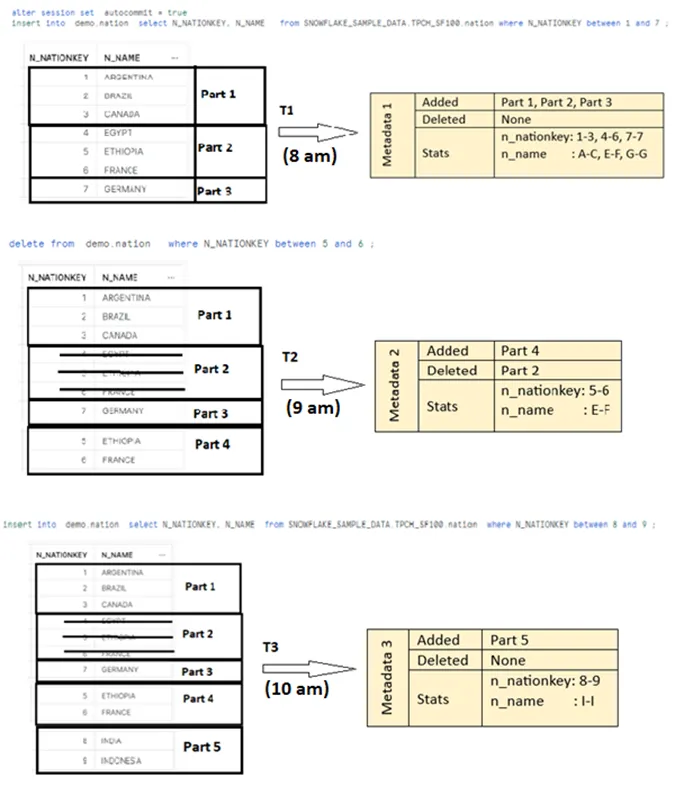
Every DML operation on a table creates a new micro-partition in database storage layer and a new metadata information in cloud services layer which points to the newly created partition. The micro-partitions are immutable, therefore modifying them is not permitted. So, instead of modifying the partitions after an update operation; a new partition is added to storage layer while Snowflake preserves the state of old partitions and keeps the old data. The old partition is signed as deleted in metadata while metadata points to the new partition that holds the updated data.
Delete operations work with a similar logic as well. The partitions holding the data which are deleted are signed as “deleted” in metadata, while files with deleted data are being kept in the storage layer for a certain amount of time before they are completely deleted. In this way the old partitions; which means the old version of the data can be queried. Metadata pointing to partitions holding the old version of data is the logic and main principle behind time travel feature.
The diagram below illustrates how micro-partitions and metadata corresponding to the micro-partitions are created after each DML operations in demo.nations table.
Old versions of data can be queried by scanning the partitions at a given time as below.
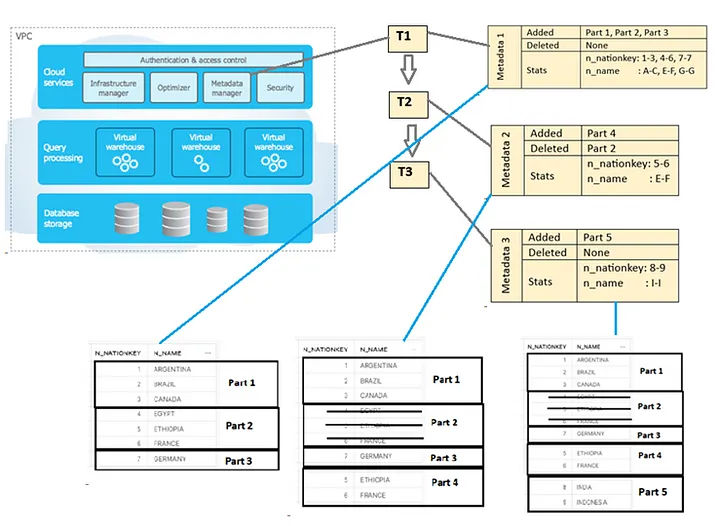
As conclusion, metadata operations simplify transaction handling, enables zero-copy cloning and time travel features. By using metadata, which holds statistics about micro-partitions at a given time gives us the possibility to query the old version of the data after update, delete, drop and truncate operations.